KI-Modell GLM-5V-Turbo verwandelt Design-Mockups direkt in lauffähigen Code
Kurz & Knapp
- Zhipu AI veröffentlicht GLM-5V-Turbo, ein multimodales Modell, das aus Bildern, Video und Text Code generiert, etwa direkt aus Design-Mockups.
- Das Modell nutzt einen eigenen Vision-Encoder und ist für Agenten-Workflows optimiert, die Wahrnehmung, Planung und Ausführung kombinieren.
- Laut Hersteller erzielt GLM-5V-Turbo starke Ergebnisse bei multimodalen Coding- und GUI-Agenten-Benchmarks, ohne bei reinen Text-Coding-Aufgaben an Leistung zu verlieren.
Das chinesische KI-Unternehmen Zhipu AI veröffentlicht mit GLM-5V-Turbo sein erstes multimodales Coding-Grundlagenmodell. Es verarbeitet Bilder, Video und Text und ist speziell für Agenten-Workflows optimiert.
Mit GLM-5V-Turbo will das Start-up die Lücke zwischen visuellem Verständnis und Codegenerierung schließen. Statt nur auf Textbasis zu arbeiten, soll das Modell etwa Design-Mockups analysieren und daraus direkt lauffähigen Code erzeugen. Laut Hersteller arbeitet es nahtlos mit Agenten wie Claude Code und OpenClaw zusammen und deckt die vollständige Schleife von "Umgebung verstehen, Aktionen planen, Aufgaben ausführen" ab.
Das Kontextfenster umfasst 200.000 Token, die maximale Ausgabe liegt bei 128.000 Token. Unterstützt werden unter anderem ein Thinking Mode, Streaming-Ausgabe, Function Calling und Context Caching.
Vier technische Ebenen sollen Vision und Code vereinen
Die Leistung von GLM-5V-Turbo fußt laut Z.AI auf systematischen Verbesserungen in vier Bereichen: Modellarchitektur, Trainingsmethoden, Datenkonstruktion und Tooling.
Bei der Architektur lernt das Modell von Beginn des Trainings an, Bilder und Text gemeinsam zu verarbeiten, statt einen separaten Bilderkennungsbaustein nachträglich an ein fertiges Sprachmodell anzudocken. Dafür hat Z.AI einen neuen Vision-Encoder namens CogViT entwickelt. Zudem sagt das Modell bei der Inferenz mehrere Token gleichzeitig voraus statt nur das jeweils nächste, was die Ausgabegeschwindigkeit erhöhen soll.
Beim Reinforcement Learning wird das Modell laut Zhipu AI über mehr als 30 Aufgabentypen hinweg gemeinsam optimiert, darunter STEM, Grounding, Video, GUI-Agenten und Coding-Agenten. Das soll zu robusteren Verbesserungen bei Wahrnehmung, Reasoning und agentischer Ausführung führen.
Um den Mangel an Agenten-Trainingsdaten zu adressieren, hat Z.AI ein mehrstufiges, kontrollierbares und verifizierbares Datensystem aufgebaut. Bereits im Pretraining fließen agentische Meta-Fähigkeiten ein, die Vorhersage und Ausführung von Aktionen stärken sollen.
Ergänzend erweitert eine neue multimodale Toolchain die Fähigkeiten des Agenten von reinem Text auf visuelle Interaktion: Werkzeuge für Box-Zeichnung, Screenshots und Webseitenlesung inklusive Bildverständnis sollen eine vollständige Wahrnehmungs-Planungs-Ausführungsschleife ermöglichen.
Benchmarks zeigen Stärken bei Coding und GUI-Agenten
In den vom Hersteller veröffentlichten Benchmarks erzielt GLM-5V-Turbo nach eigenen Angaben führende Ergebnisse bei multimodalen Coding- und Agenten-Aufgaben. Das Modell schneidet demnach stark ab bei Design-to-Code-Generierung, visueller Codegenerierung, multimodaler Suche und visueller Exploration. Auch bei AndroidWorld und WebVoyager, zwei Benchmarks für die Fähigkeit eines Agenten, in realen GUI-Umgebungen zu operieren, meldet Z.AI starke Ergebnisse.
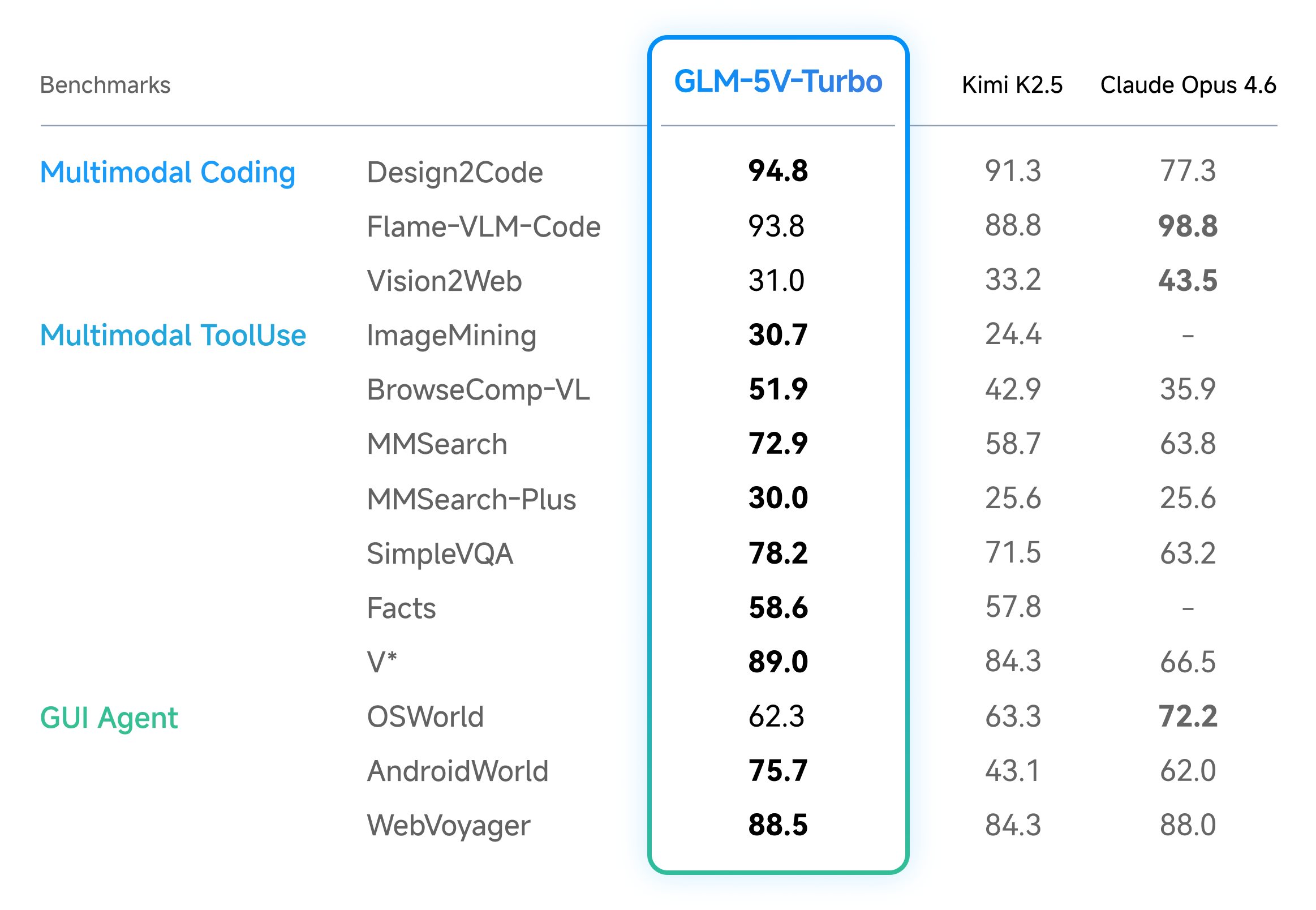
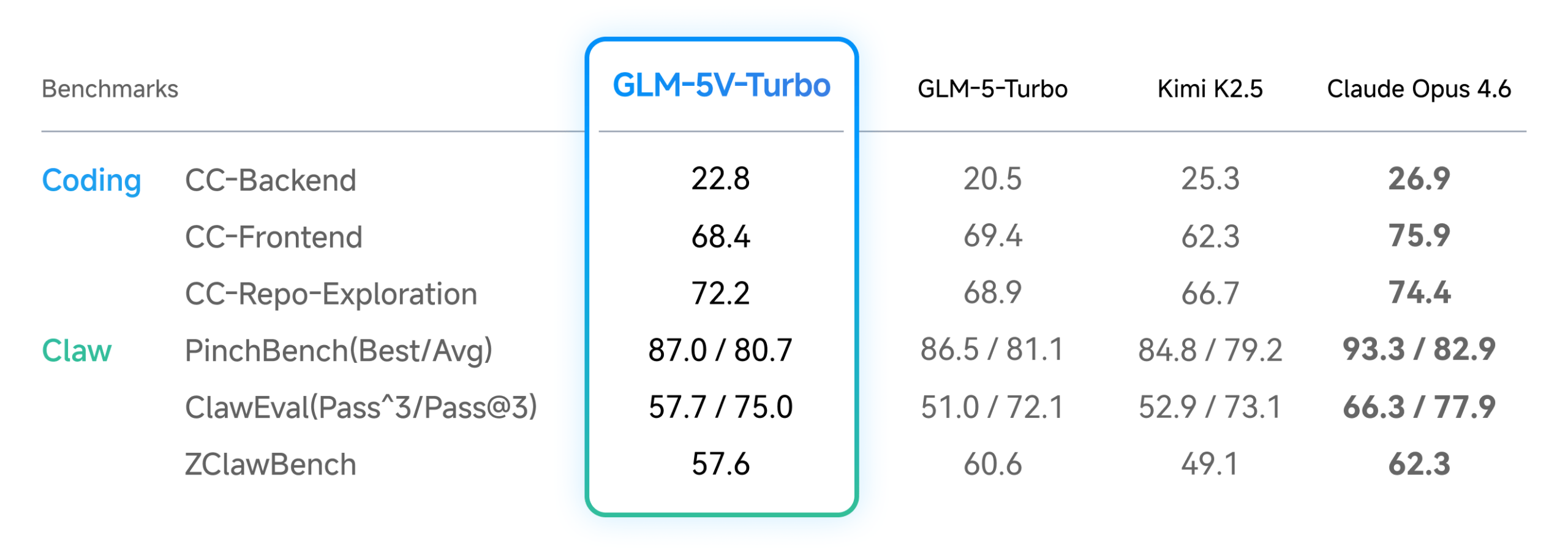
Bei reinen Text-Coding-Aufgaben soll GLM-5V-Turbo trotz der hinzugekommenen visuellen Fähigkeiten keine Leistungseinbußen zeigen. In den drei Kernbenchmarks von CC-Bench-V2 (Backend, Frontend, Repo Exploration) hält das Modell laut Hersteller seine Leistung. Dazu kommen starke Ergebnisse bei PinchBench, ClawEval und ZClawBench, die die Qualität der Aufgabenausführung bewerten sollen. Unabhängige Evaluierungen stehen allerdings noch aus.
Von Mockups zu Code: Anwendungsfälle und offizielle Skills
GLM-5V-Turbo zielt auf mehrere konkrete Einsatzszenarien. Beim Frontend-Nachbau analysiert das Modell laut Z.AI Design-Mockups oder Referenzbilder und generiert daraus ein vollständiges, lauffähiges Frontend-Projekt. Bei Wireframes rekonstruiert es Struktur und Funktionalität, bei hochauflösenden Designs strebt es pixelgenaue visuelle Konsistenz an.
In Kombination mit Frameworks wie Claude Code soll das Modell auch zur autonomen GUI-Exploration fähig sein: Es durchsucht selbstständig Zielwebsites, kartiert Seitenübergänge, sammelt visuelle Assets und Interaktionsdetails und generiert Code auf Basis der Erkundungsergebnisse. Z.AI spricht von einem Upgrade "vom Nachbau aus einem Screenshot zum Nachbau durch autonome Exploration".
Für Code-Debugging nimmt das Modell Screenshots fehlerhafter Seiten entgegen, identifiziert laut Z.AI automatisch Rendering-Probleme wie Layout-Verschiebungen, Komponentenüberlappungen und Farbabweichungen und generiert entsprechenden Fix-Code. Nach Integration von GLM-5V-Turbo soll auch OpenClaw Webseitenlayouts, GUI-Elemente und Diagramminformationen verstehen können, was dem Agenten bei komplexen Aufgaben helfen soll, die Wahrnehmung, Planung und Ausführung kombinieren.
Z.AI stellt darüber hinaus eine Reihe offizieller Skills bereit, darunter Image Captioning, Visual Grounding, dokumentenbasiertes Schreiben, Lebenslauf-Screening und Prompt-Generierung. Alle sind auf der Plattform ClawHub verfügbar.
GLM-5V-Turbo ist vorerst nur als API-Dienst über die Z.AI-Plattform verfügbar. Die Preise liegen bei 1,20 Dollar pro Million Input-Token und 4 Dollar pro Million Output-Token, damit genauso teuer wie das reine Textmodell GLM-5-Turbo und etwas teurer als das Basismodell GLM-5. Offene Modellgewichte hat Z.AI bislang nicht angekündigt.
GLM-5-Turbo und GLM-5 als Vorgänger
Vor kurzem hatte Z.AI bereits GLM-5-Turbo vorgestellt, ein reines Textmodell, das speziell für das OpenClaw-Agenten-Framework optimiert wurde. Es stärkt laut Hersteller gezielt Tool-Aufrufe, Instruktionsbefolgung, zeitgesteuerte und persistente Aufgaben sowie die Ausführung langer Aufgabenketten.
Zusammen mit GLM-5-Turbo führte Z.AI den ZClawBench ein, einen End-to-End-Benchmark für Agenten-Aufgaben im OpenClaw-Ökosystem. Die Ergebnisse zeigen laut Hersteller, dass GLM-5-Turbo gegenüber dem Vorgänger GLM-5 deutlich zulegt und in mehreren Aufgabenkategorien Modelle wie Claude Opus 4.6, Gemini 3.1 Pro, MiniMax M2.5 und Kimi K2.5 hinter sich lässt. Parallel dazu stieg die Nutzung von Skills im OpenClaw-Ökosystem laut Z.AI in kurzer Zeit von 26 auf 45 Prozent, ein Indiz für den wachsenden Trend zu modularen Agenten-Systemen.
Davor hatte Zhipu AI Mitte Februar mit GLM-5 ein Open-Source-Modell mit 744 Milliarden Parametern unter MIT-Lizenz veröffentlicht, das bei Coding und agentenbasierten Aufgaben laut Herstellerangaben mit Claude Opus 4.5 und GPT-5.2 mithalten kann. GLM-5 erreichte beim SWE-bench Verified 77,8 Prozent und lag damit knapp hinter Claude Opus 4.5 mit 80,9 Prozent. Das Modell läuft neben Nvidia-GPUs auch auf chinesischen Chips von Huawei und anderen Herstellern, ein wesentlicher Vorteil angesichts der US-Exportbeschränkungen.
Auch Alibaba verfolgt mit Qwen3.5-Omni einen vergleichbaren Ansatz: Das omnimodale Modell verarbeitet Text, Bilder, Audio und Video. Ähnlich wie GLM-5V-Turbo kann es aus visuellen Eingaben direkt Code generieren, nimmt dabei aber zusätzlich gesprochene Anweisungen entgegen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren